I stumbled upon this official MoMa dataset outlining 138.185 artworks from their collection. Surprised to find nobody had published any analysis or visualizations of it before, my decision was quickly made. The resulting insights were interesting and perhaps useful for further research so I decided to share them in an article published on Towards Data Science.
The blog outlines:
In  research framework, I state the goal of the research and sketch the context of diversity in modern art institutions and the MoMa in particular.
research framework, I state the goal of the research and sketch the context of diversity in modern art institutions and the MoMa in particular.
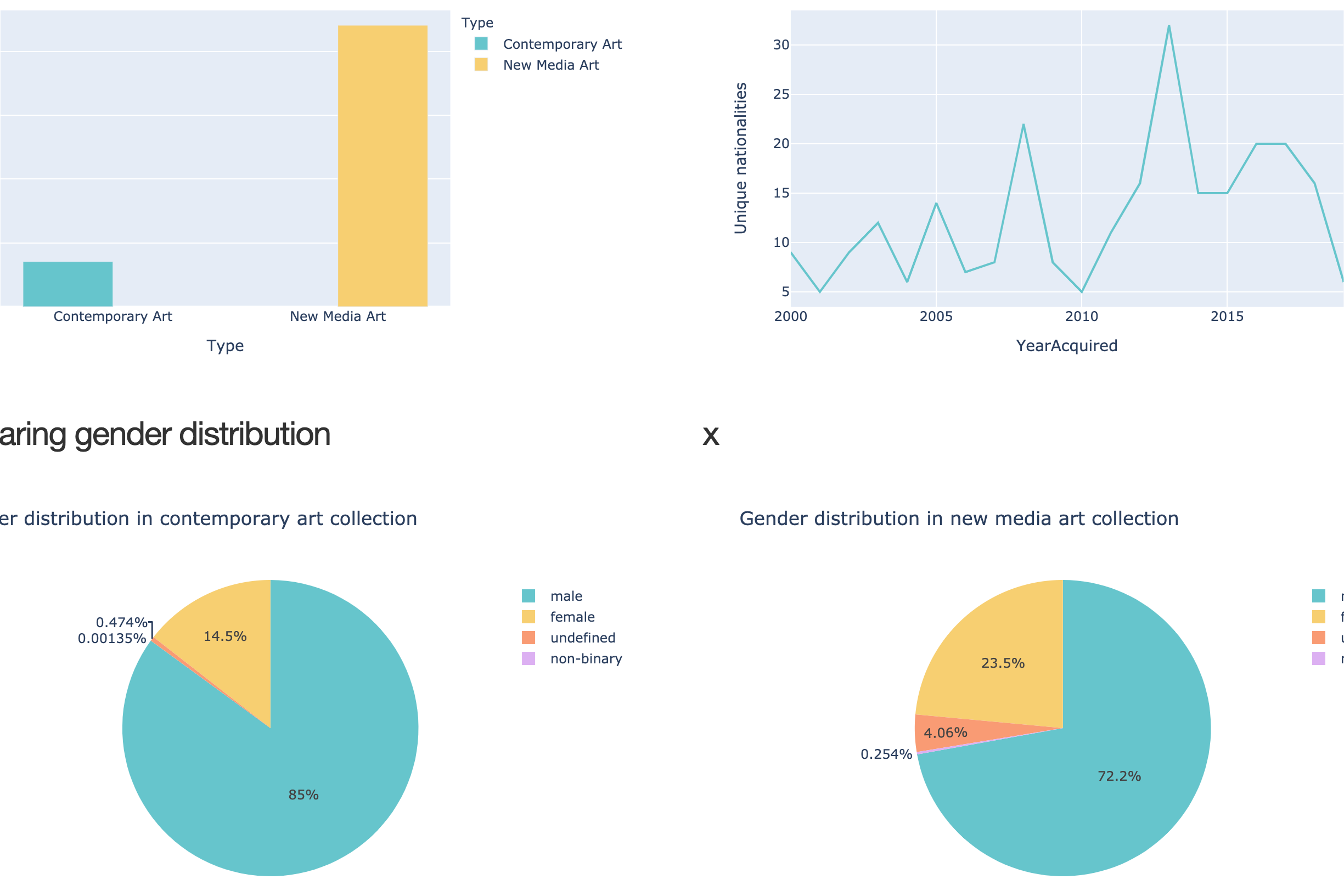
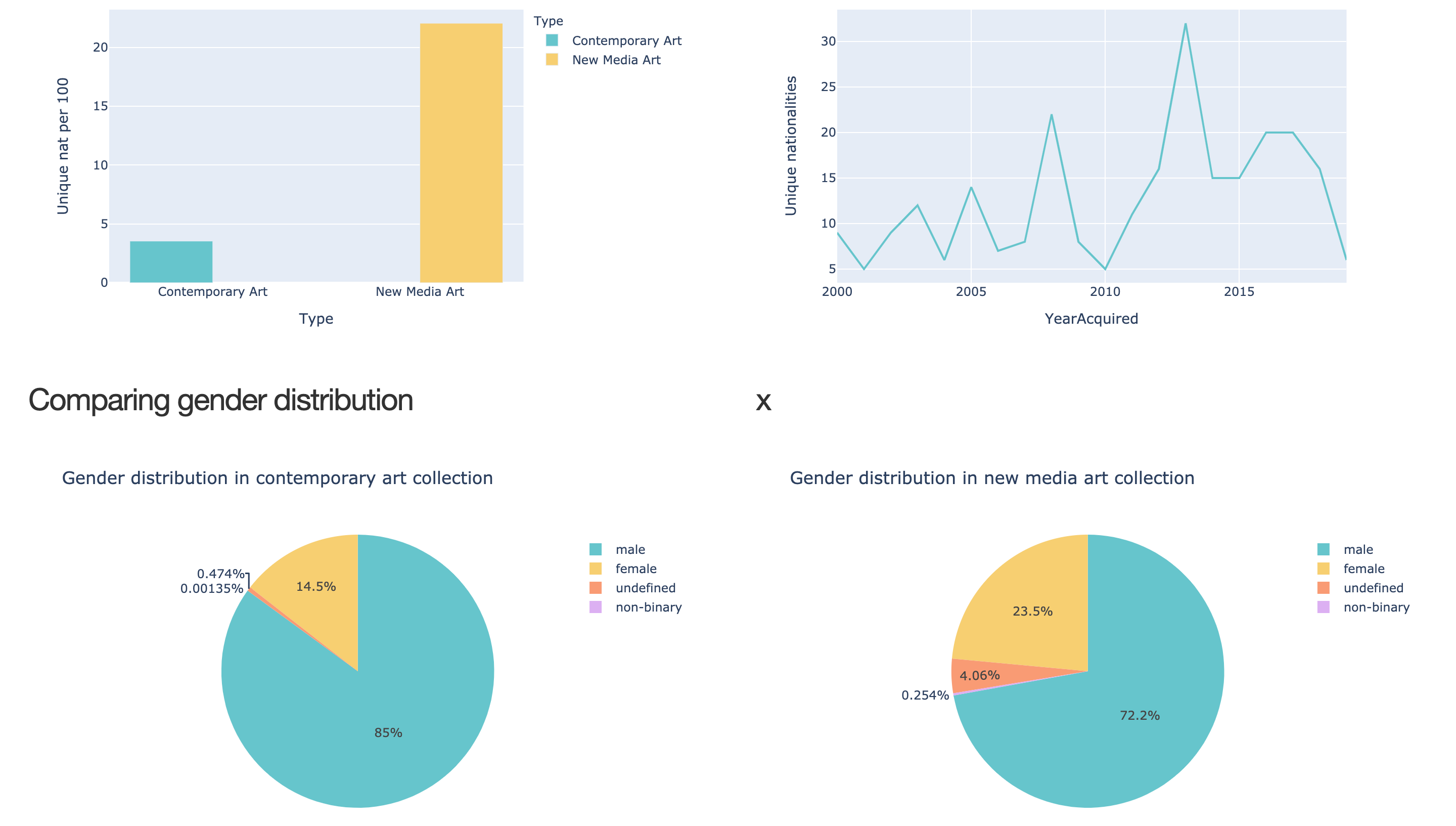
In  data insights, I show the results from the analysis illustrated with colorful graphs and accompanied by a conclusion and discussions.
data insights, I show the results from the analysis illustrated with colorful graphs and accompanied by a conclusion and discussions.
In  methodology, I detail the process and decisions made in data cleaning and pre-processing using largely Python, Pandas, and Plotly.
methodology, I detail the process and decisions made in data cleaning and pre-processing using largely Python, Pandas, and Plotly.